[ Mesh Shaders and Meshlet Culling ]
I recently became interested in the amplification/mesh pipeline, a relatively new rendering pipeline for modern GPUs.
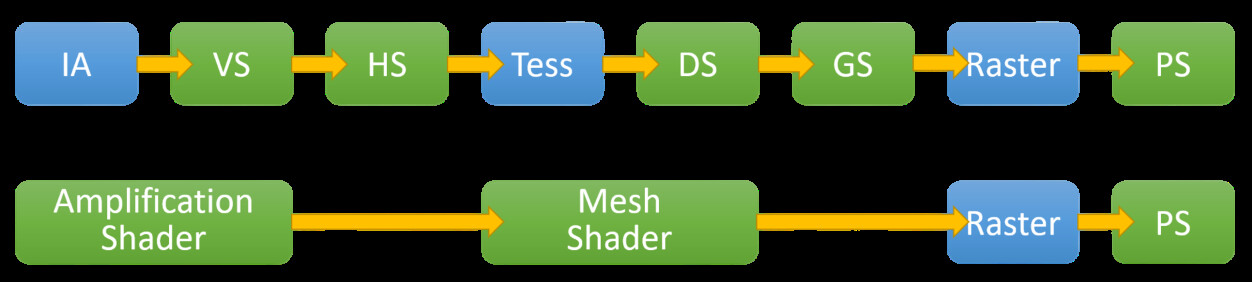
So I experimented with a basic DirectX/Vulkan renderer that divides meshes into meshlets and frustum culls them on the GPU.
Here's the result, with frustum culling occupying 1/4 of the window resolution in the center.
And here it is with the correct frustum culling size and without debug colors.
Code available as ZIP download.
[ DirectX / Vulkan Abstraction ]
First of all, I wanted my engine to work with DirectX and Vulkan. To do this, I needed an abstraction layer, but just for my simple needs, which are prototyping, so that everything is kept to a minimum for fast iteration time. I'm not trying to build a production-ready engine.
My main rendering class is a virtual singleton class, which can be templated for either API, here's a simplified version of the virtual definition, nothing special here:
class Renderer : public Singleton
{
public:
virtual void CreateDevice() = 0;
virtual void CreateSwapchain() = 0;
virtual void CreateFence(u32 idx) = 0;
virtual void CreateCommandLists(u32 idx) = 0;
virtual void SetPipelineState(void amplificationShaderHandle, u32 meshShaderHandle, u32 pixelShaderHandle) = 0;
virtual u32 CreateBuffer(BufferType type, u32 sizeInBytes, u32 strideInBytes, const string& name, AllocType allocType = CE_BUFFER_ALLOC_TYPE_Default) = 0;
virtual u32 LoadShader(ShaderType type, const std::wstring& filename) = 0;
virtual u32 LoadModel(const std::wstring& filename) = 0;
virtual void Present() = 0;
virtual void GetOrWaitNextFrame() = 0;
virtual void WaitAllFrames() = 0;
virtual SharedPtr GetCurrentContext() = 0;
protected:
u32 m_FrameIdx = 0;
}; Perhaps you've noticed methods returning a u32. When the renderer needs to return data, instead of having an API-templated structure (like one to handle VkBuffer/ID3D12Resource), I decided to just have a handle, which is an index into an array holding the data, which may be considered less clean but I really like its simplicity, even if debugging can be more difficult.
Here is an example of a handle being created:
u32 Renderer_DX12::LoadShader(const ShaderType type, const std::wstring& filename)
{
IDxcBlob* result = CompileShader(type, filename);
const D3D12_SHADER_BYTECODE byteCode =
{
.pShaderBytecode = result->GetBufferPointer(),
.BytecodeLength = result->GetBufferSize(),
};
m_Shaders.push_back(byteCode);
std::wcout << "Shader " << m_Shaders.size()-1 << " loaded. (" << filename.c_str() << ")\n";
return m_Shaders.size() - 1;
}Right now there's no handle deletion system; I don't need it yet :^)
[ Meshlet generation and culling ]
Time for the main course. Using meshoptimizer, I start by generating meshlets (a group of spatially close triangles) of the mesh. Here's a close-up view of these meshlets, with each color corresponding to a different meshlet.

Also, using the same library, I generate each meshlet's bounding sphere and normal cone. Using these meshlet boundaries, in the Amplification Shader stage, I can select only the meshlets visible to the camera frustum to be dispatched into the Mesh Shader stage.
Here's the code for the amplification shader, responsible for culling meshlets:
#include "Common.hlsli"
groupshared Payload s_Payload;
bool IsVisible(MeshletBounds bounds, float4x4 world, float3 viewPos)
{
// Frustum culling
float4 center = mul(float4(bounds.center, 1), world);
float radius = bounds.radius;
for (int i = 0; i < 6; ++i)
{
if (dot(center, Globals.Planes[i]) < -radius)
{
return false;
}
}
// Backface culling
if (dot(normalize(bounds.cone_apex - viewPos), bounds.cone_axis) >= bounds.cone_cutoff)
{
return false;
}
return true;
}
[RootSignature(ROOT_SIG)]
[NumThreads(32, 1, 1)]
void main(uint gtid : SV_GroupThreadID, uint dtid : SV_DispatchThreadID, uint gid : SV_GroupID)
{
bool visible = false;
// Check bounds of meshlet cull data resource
if (dtid < Globals.MeshletCount)
{
visible = IsVisible(MeshletBoundsBuffer[dtid], Globals.World, Globals.CameraPos);
}
// Compact visible meshlets into the export payload array
if (visible)
{
uint index = WavePrefixCountBits(visible);
s_Payload.MeshletIndices[index] = dtid;
}
// Dispatch the required number of MS threadgroups to render the visible meshlets
uint visibleCount = WaveActiveCountBits(visible);
DispatchMesh(visibleCount, 1, 1, s_Payload);
}Now that only visible meshlets are sent to the Mesh Shader stage, we can decode their triangles. Fortunately, meshoptimizer provides the buffers I send to the GPU to retrieve all the necessary triangle data for each meshlet.
Here is the code for the mesh shader, responsible for producing the visible meshlets' triangles:
#include "Common.hlsli"
uint3 GetTriangle(Meshlet m, uint index)
{
return uint3( MeshletTriangles[2 + m.triangleOffset + index * 3],
MeshletTriangles[1 + m.triangleOffset + index * 3],
MeshletTriangles[0 + m.triangleOffset + index * 3] );
}
uint GetVertexIndex(Meshlet m, uint index)
{
return MeshletVertices[(m.vertexOffset + index)];
}
VertexOut GetVertexAttributes(uint meshletIndex, uint vertexIndex)
{
Vertex v = Vertices[vertexIndex];
VertexOut vout;
vout.PositionVS = mul(float4(v.Position, 1), Globals.WorldView).xyz;
vout.PositionHS = mul(float4(v.Position, 1), Globals.WorldViewProj);
vout.Normal = mul(float4(v.Normal, 0), Globals.World).xyz;
vout.MeshletIndex = meshletIndex;
return vout;
}
[RootSignature(ROOT_SIG)]
[OutputTopology("triangle")]
[NumThreads(124, 1, 1)]
void main(
in uint gtid : SV_GroupThreadID,
in uint gid : SV_GroupID,
in payload Payload payload,
out indices uint3 tris[124],
out vertices VertexOut verts[64]
)
{
uint meshletIndex = payload.MeshletIndices[gid];
if (meshletIndex >= Globals.MeshletCount)
{
return;
}
Meshlet m = Meshlets[meshletIndex];
SetMeshOutputCounts(m.vertexCount, m.triangleCount);
if (gtid < m.triangleCount)
{
tris[gtid] = GetTriangle(m, gtid);
}
if (gtid < m.vertexCount)
{
const uint vertexIndex = GetVertexIndex(m, gtid);
verts[gtid] = GetVertexAttributes(gid, vertexIndex);
}
}And voila, simple as that!
[ Benchmarks and final thoughts ]
With meshlet culling, which mesh shaders make easy, the performance gain is massive.
| Amazon Lumberyard Bistro exterior scene | DX12 (fps) | VK (fps) |
|---|---|---|
| No Culling | 1318 | 1557 |
| Frustum Culling | 1696 (+28.67%) | 2311 (+48.42%) |
| Frustum + Backface Culling | 1725 (+30.88%) | 2317 (+48.81%) |
Note that my current renderer is very simple, using only a single forward pass with basic Blinn-Phong shading. I suspect this culling could have a better impact on a heavier rendering pipeline, for example when used with Cascaded Shadow Maps, by filtering all geometry outside the shadow visibility frustum of each cascade.
In conclusion, I really like this pipeline and this method, which are both simple and offer good performance gains. I'll probably continue to use it for my test engine.
[ References ]
- DirectX Graphics Samples : Mesh Shaders - Microsoft. github.com/microsoft/DirectX-Graphics-Samples/tree/master/Samples/Desktop/D3D12MeshShaders
- Introduction to Turing Mesh Shaders - Christoph Kubisch, Nvidia. developer.nvidia.com/blog/introduction-turing-mesh-shaders
- DirectX-Specs : Mesh Shader - Microsoft. microsoft.github.io/DirectX-Specs/d3d/MeshShader.html
- Mesh Shading for Vulkan - Christoph Kubisch, Nvidia. khronos.org/blog/mesh-shading-for-vulkan
- Meshoptimizer - Arseny Kapoulkine. github.com/zeux/meshoptimizer